Amazon Redshift is a managed data warehouse service that offers complex data analysis queries, performant queries, and petabyte-scale storage. Redshift is a relational database management system (RDBMS). A Redshift cluster consists of one or more compute nodes. If the number of compute nodes exceeds one, the cluster includes a leader node to coordinate the compute nodes and interact with external clients. External clients interact with a Redshift cluster via the leader node using an ODBC or JDBC driver.
The leader node manages complex queries by developing an execution plan, which consists of compiling the code and distributing it to the compute nodes along with the requisite data. The compute nodes run the compiled code and send intermediate results back to the leader node, which aggregates the results. By default the leader node runs all SQL statements (queries) and sends the statements to compute nodes only if the statements reference data that is stored on a compute node. Certain SQL functions run only on the leader node and must not reference tables stored on a compute node. If a cluster consists of single node it is both the leader node and compute node.
|
NOTE: In an earlier tutorial Using Amazon Redshift with Toad Data Point we discussed using Redshift with Toad Data Point. This tutorial is different in that Toad Edge makes use of a JDBC driver to connect to Redshift while Toad Data Point makes use of an ODBC driver. Amazon Redshift-specific JDBC and ODBC drivers are available. Which to use, JDBC or ODBC, is mainly dependent on the client tool/s available, as both offer comparable performance. ODBC is more complex to configure, as an ODBC driver has to be installed and a System DSN (Data Source Name) added. Configuring JDBC only involves the JDBC driver to be added to the class path of the client tool. |
In two articles we shall discuss using Toad Edge 2.0.2 with Redshift. The two articles have the following sections.
Setting the Environment
Installing Redshift JDBC Driver
Creating a Connection
Creating a Database Table
Querying Table
Displaying Result
Exporting Query Result
Creating Multiple Connections
Disconnecting and Reconnecting
Dropping Table
Deleting Cluster
Try Toad Edge free for 30 daysFree 30-day trial of Toad Edge Already in a trial? If Toad Edge has helped you ramp up on open source RDBMSs fast, buy it now or contact a sales representative. |
Setting the Environment
Download and install Toad Edge 2.0.2. Create an AWS account.
The procedure to create and configure a Redshift cluster is as follows.
- Create a VPC for Redshift
- Add Subnets to VPC
- Add an Internet Gateway
- Create a Redshift Cluster Subnet Group for Redshift
- Create a Redshift Cluster consisting of one compute node
- Modify Route Table for VPC
- Modify default Security Group Inbound/Outbound Rules
Create a Redshift cluster as discussed in earlier tutorial Using Amazon Redshift with Toad Data Point.
Obtain the Endpoint for the Redshift cluster from the console as shown in Figure 1. Database Name is redshiftdb and Port is 5439 as listed in Figure 1. These are the only connection parameters needed in addition to username and password.
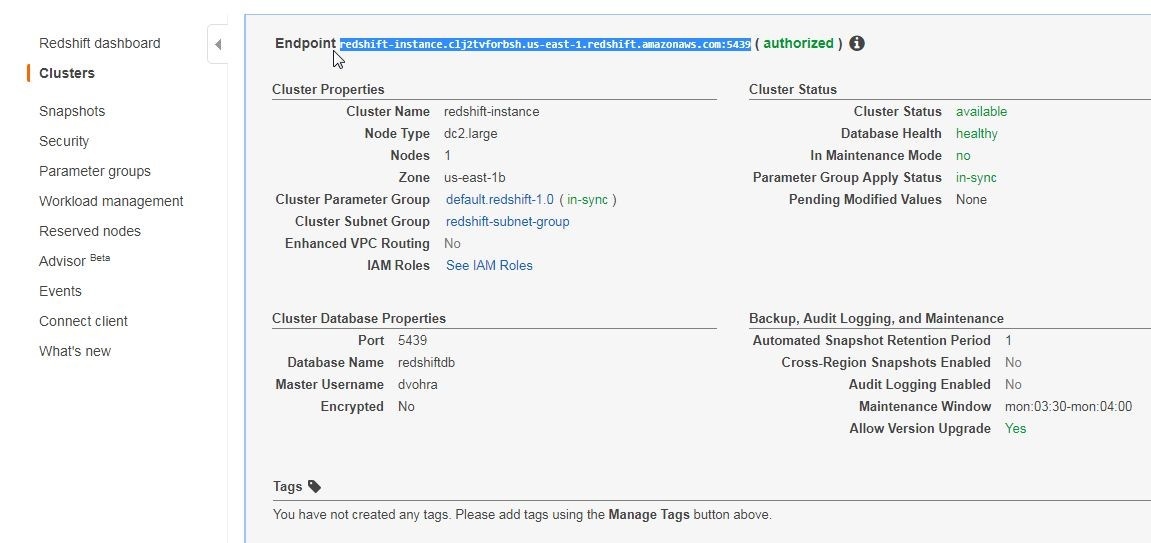
Figure 1. Obtaining Connection Parameters for Redshift
Installing Redshift JDBC Driver
In this section we shall install the JDBC driver for Redshift in Toad Edge 2.0.2. Redshift provides three versions of JDBC jars, one each for JDBC 4.0, 4.1 and 4.2. Toad Edge only supports the JDBC 4.2 jar. First download the JDBC driver RedshiftJDBC42-1.2.16.1027.jar from https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.16.1027/RedshiftJDBC42-1.2.16.1027.jar .
Click on Tools>Preferences in Toad Edge as shown in Figure 2.
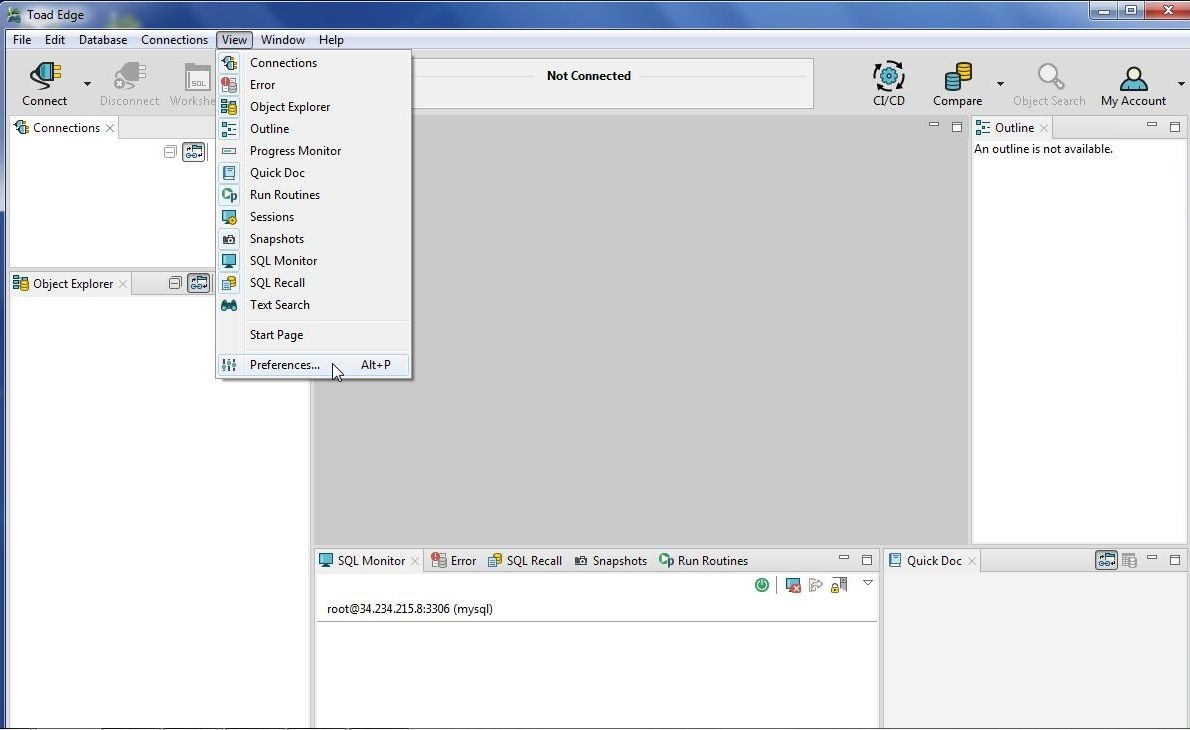
Figure 2. Tools>Preferences
In Preferences select Database button and Redshift (Beta) tab as shown in Figure 3. Click on Add… .
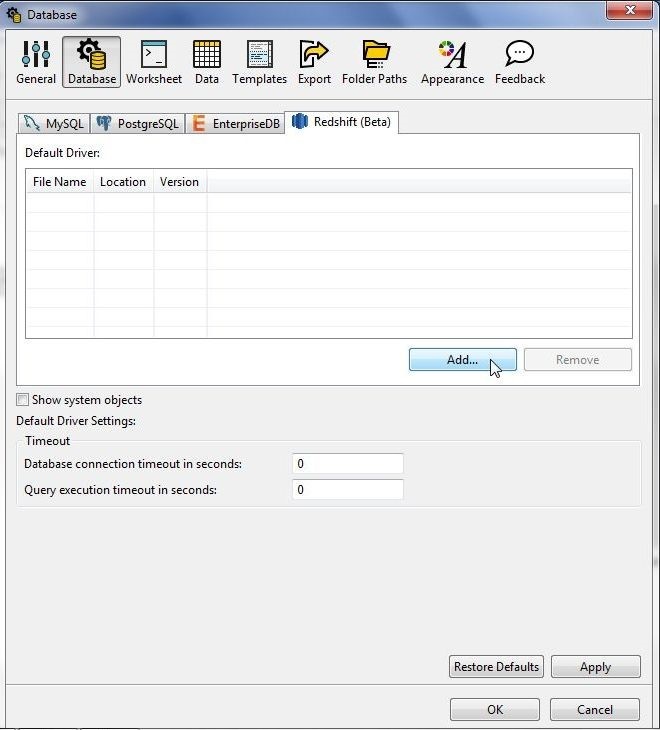
Figure 3. Database>Redshift>Add
In the Open dialog select the RedshiftJDBC42-1.2.16.1027.jar from the folder in which it is downloaded and click on Open. The Redshift JDBC 4.2 driver gets loaded, as shown in Figure 4. Click on Apply. Click on OK.
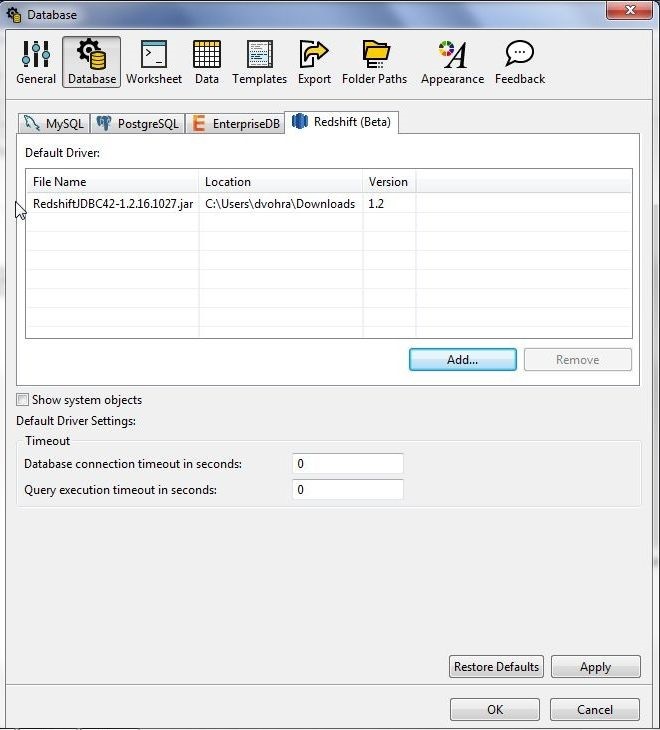
Figure 4. Redshift JDBC 4.2 Driver loaded
Creating a Connection
To create a connection to Redshift select Connect>New Connection as shown in Figure 5.
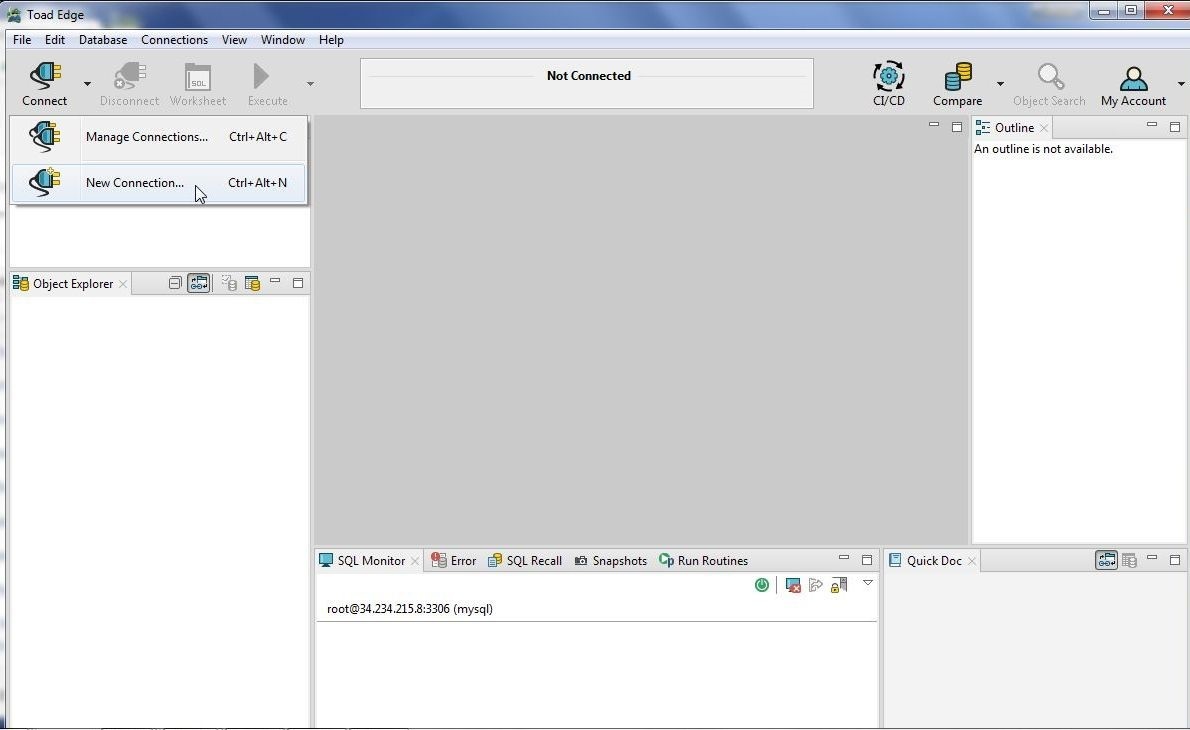
Figure 5. Connect>New Connection
In New Connection wizard select Database Platform as Redshift and click on Next as shown in Figure 6.
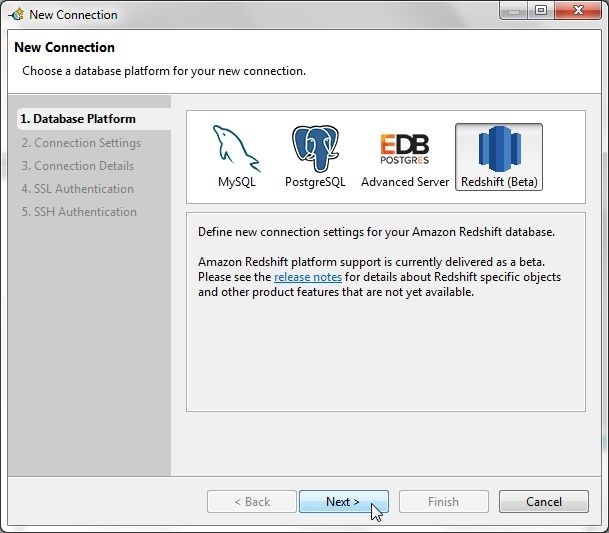
Figure 6. New Connection>Redshift>Next
Next, specify the Connection Settings. Specify Hostname as the Endpoint obtained from the Redshift cluster console in Figure 1. Specify Database as redshiftdb and Port as 5439, also obtained from the Redshift console. Specify the Username and Password configured for the Redshift cluster. The connection string is displayed, and may be customized by selecting the Custom Connection String checkbox. We don’t need to customize the connection string. Click on Test Connection to test the connection as shown in Figure 7.
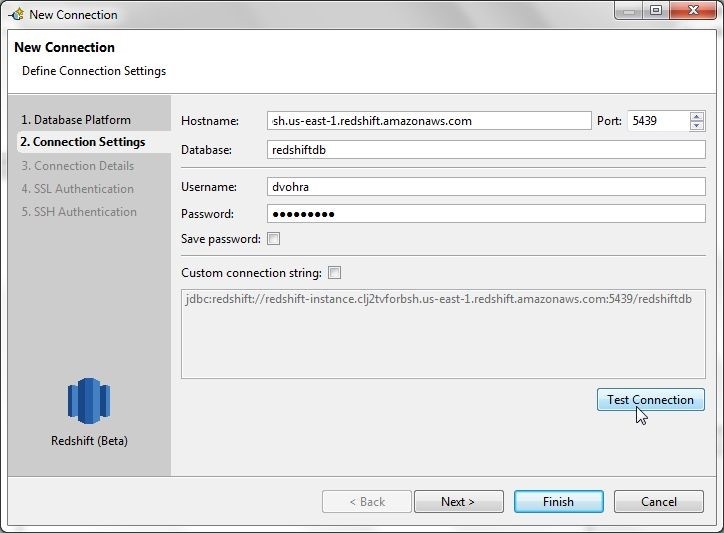
Figure 7. Connection Settings>Test Connection
The message Connection is OK in Figure 8 indicates that the connection gets established. Click on Next.
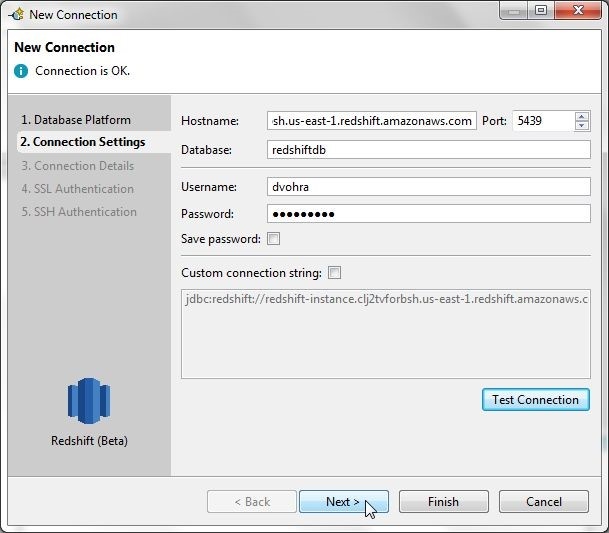
Figure 8. Connection is OK>Next
In Connection Details (Figure 9) the Connection name is displayed, which may optionally be modified. The Connection color may optionally be set. Click on Finish.
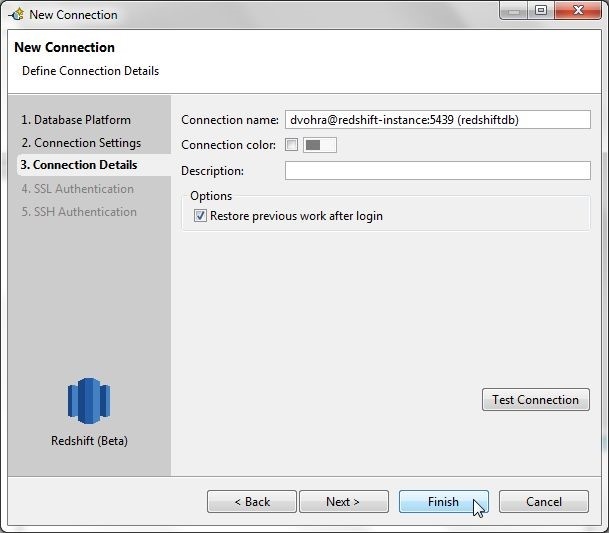
Figure 9. Connection Details
A new connection gets created, as shown in Connections view in Figure 10. The Object Explorer displays the Schemas, Databases, and Catalogs. Redshift has only one schema by default, public schema. Redshift is based on PostgreSQL 8.0.2, from which it gets the public schema.
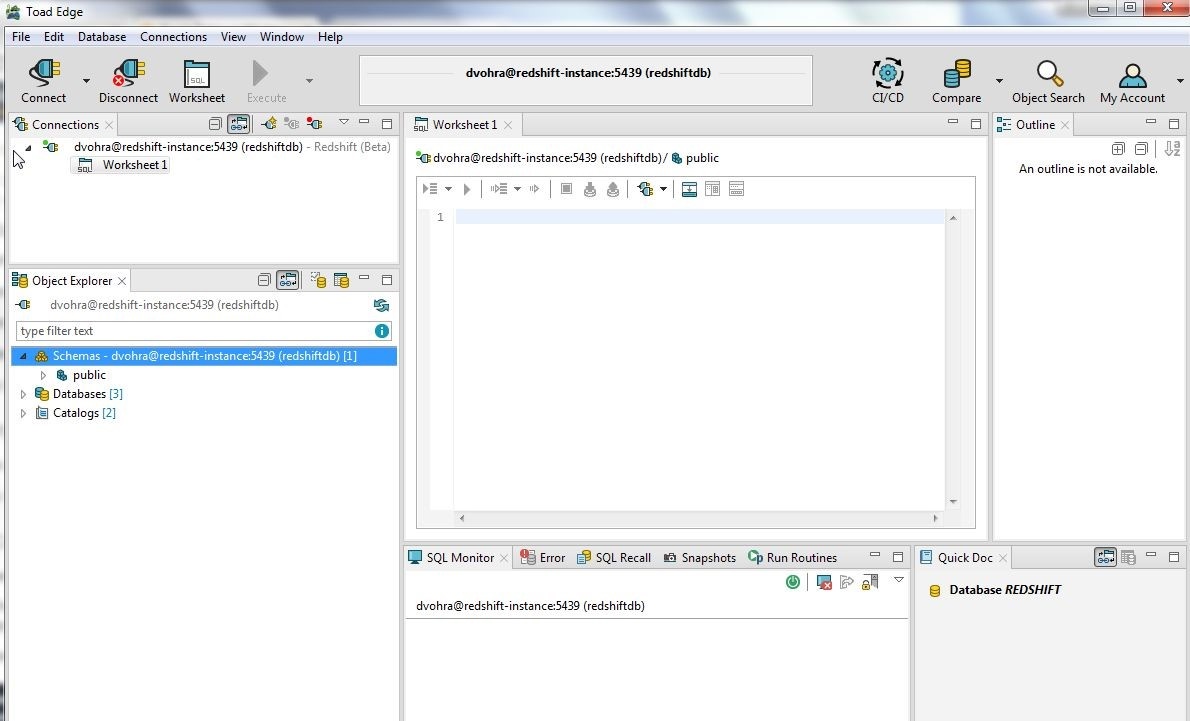
Figure 10. New Connection added
To refresh the tables right-click on the Tables in Object Explorer and select Refresh as shown in Figure 11.
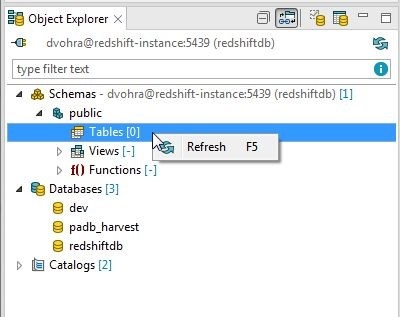
Figure 11. Tables>Refresh
To refresh the databases right-click on Databases and select Refresh as shown in Figure 12.
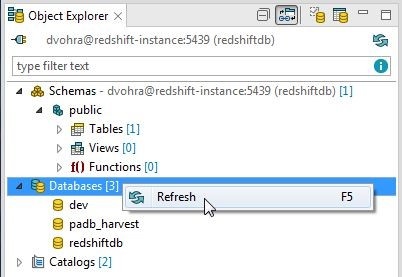
Figure 12. Databases>Refresh
The redshiftdb is the user-created database and the other two databases are the default included databases. To refresh or drop the redshiftdb database right-click on the database and select from the Refresh and Drop options as shown in Figure 13.
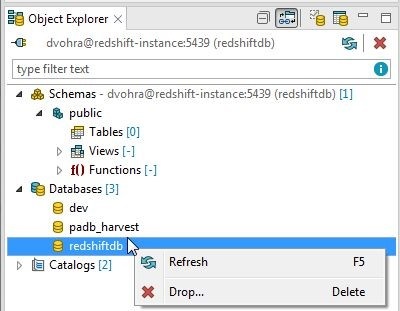
Figure 13. Databases>redshiftdb Options
By default a new connection is associated with one SQL Worksheet; additional worksheets may be added as shown in Figure 14.
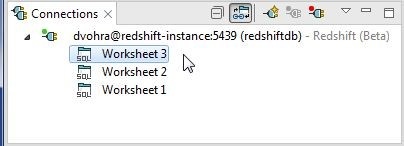
Figure 14. SQL Worksheets
Summary
In the first of two articles on using Toad Edge with Amazon Redshift we have discussed how Toad Edge is different from Toad Data Point when used with Redshift. We installed the JDBC 4.2 driver (JDBC 4.0 and 4.1 are not supported) for Redshift and configured the same in Toad Edge. Subsequently we created a connection in Toad Edge to Redshift. In a subsequent article we shall discuss using some of the Toad Edge features for Redshift.
Want to learn more?User guide: Access the Toad Edge User Guide. Product page: Click the following link to watch a video on our product page and learn how Toad Edge can help you simplify development and management tasks for open source databases. Blog: 7 hacks to use Toad Edge like a boss Blog: 5 blogs that teach you to effectively work in Toad Edge® |
Start the discussion at forums.toadworld.com