Microsoft has been extremely innovative the past few years – especially with regard to their SQL Server relational database both on premise and in the cloud. Although I am a Linux bigot and love the fact that Microsoft now offers SQL Server on Linux, that’s not the most interesting new development. I also like their new pricing vs. feature structure – that all editions now offer almost all features, the only limiting factor being maximum CPU, memory and database size. That makes database upgrades painless with zero application changes required. But arguably the most interesting and disruptive new feature is the “stretch database”, which basically allows your on premise database to store a portion of your data as normal and the rest in the cloud – with total transparency to the application and end users. Some users adopt this feature to slowly migrate to the cloud while others to leverage the cloud’s infinite scalability in order to keep colder data online for longer period of time as required by the business. Here is a basic diagram depicting this concept and feature. Note that SQL Server’s query optimizer handles this division of data totally transparently. Thus a big table logically looks like it’s all local when in fact part of it is on premise and part of it is in the cloud as shown here.
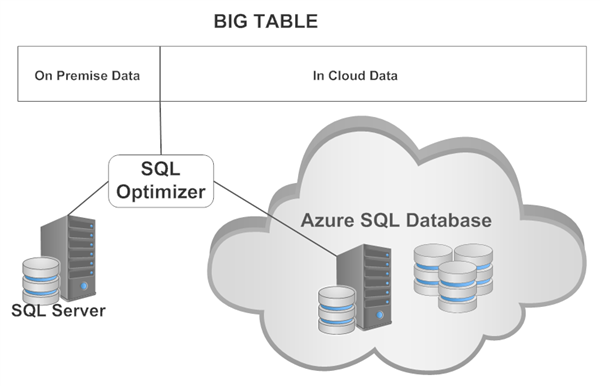
But as interesting as this capability is, it has some key limitations. First is requires SQL Server 2016 or greater and it can only stretch into Microsoft Azure SQL database. So it is limited to both one database and one cloud provider. Furthermore there are several key data type, constraint and DML operations limits which further complicate this solution. Moreover the costs for leveraging this capability are more costly than many find acceptable since one must pay several fees – basic cloud storage, database stretch units (DSUs) which are the computing power to process stretch processing and outbound data transfers.
What many people would prefer is this exact same capability for any on premise database stretched into any cloud provider with the target database being any database (i.e. not require same database on both sides) and without data type or other limits. Such a solution does exist! Cirro’s federated query engine provides the capability to create a “partition view” tables regardless of their database platform. You can stretch for example Oracle on premise to PostgreSQL on Amazon RDS. In fact you can stretch tables for any number of tables either on premise or in the cloud and across any number of database platforms. So the figure shown below highlights only the most basic scenario.
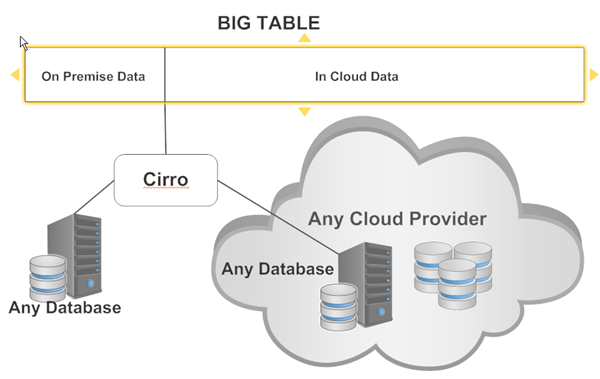
Below is the Cirro partition view definition required to stretch my two largest, on premise Oracle tables to PostgreSQL on Amazon RDS. I keep roughly 10% of the hottest data on premise and 90% of the colder data in the cloud.
create partition view stretch_table_1 as
select * from ORACLE.ORCL.stretch.table_1a partition by range on c1 (minvalue, 1000)
union all
select * from POSTGRESQL.stretch.stretch.table_1b partition by range on c1 (1000,maxvalue);
create partition view stretch_table_2 as
select * from ORACLE.ORCL.stretch.table_2a partition by range on c1 (minvalue, 1000)
union all
select * from POSTGRESQL.stretch.stretch.table_2b partition by range on c1 (1000,maxvalue);
Then from the end users’ perspective they simply query the Cirro view and Cirro automagically handles optimizing the query and returning the results. Note in this example below the user has two tables with some portions on premise and in the cloud, and performs SQL join operations without issue. Now that’s what I call truly stretching databases and tables. And only Cirro currently offers this.
select * from stretch_table_1 t1 join stretch_table_2 t2 on (t1.c1 = t2.c1)
where t1.c1 between 500 and 2500 and t2.c2 between 4 and 6;
Start the discussion at forums.toadworld.com