If you want to access MySQL Cloud Service using Zeppelin of Oracle Big Data Cloud Service Compute Edition (BDCSCE), you can use Spark DataFrames or Zeppelin interpreters. In this blog post, I’ll show how we can edit JDBC interpreter to connect MySQL Cloud Service.
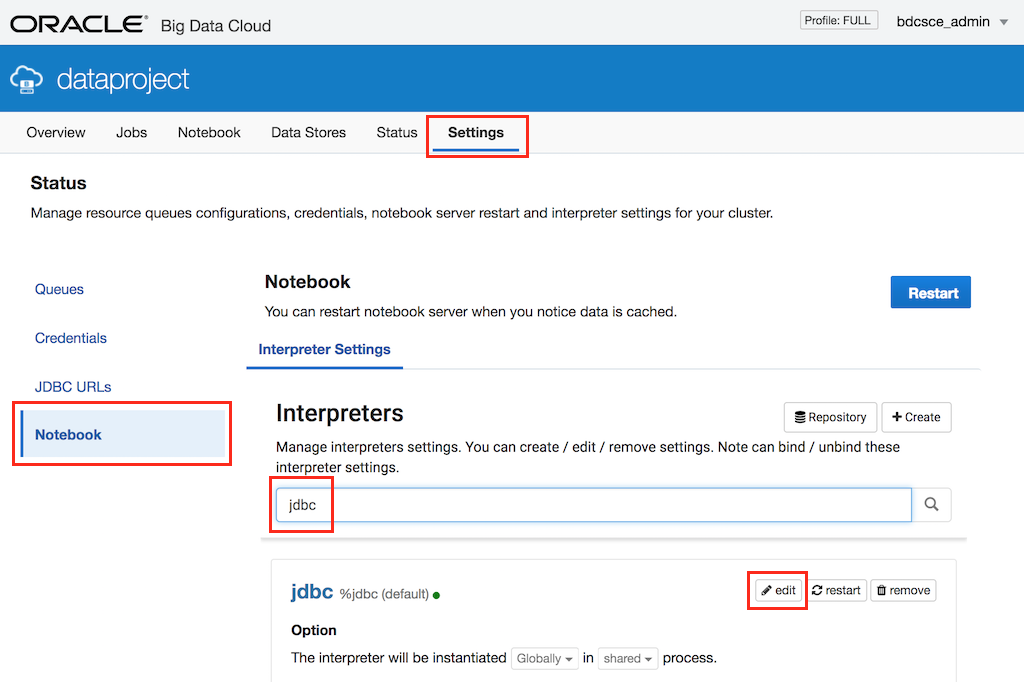
First login to Oracle Big Data Cloud console, and go to “settings” tab, and open “notebook” section. You’ll see the interpreter settings. Search for “jdbc” and click “edit” button to edit the interpreter settings.

MySQL connector is already included in Zeppelin coming with Oracle Big Data Compute Edition service, but if it’s not included, download “MySQL Connector/J” from mysql.com to your Zeppelin server, and add the path to the dependencies. Add the required the following to the properties:
mysql.user – the mysql user name you will use to connect the DB
mysql.password – plain text password (it will be encrypted by Zeppelin)
mysql.url – the connection URL (something like jdbc:mysql://servername:3306/dbname)
mysql.driver – com.mysql.jdbc.Driver
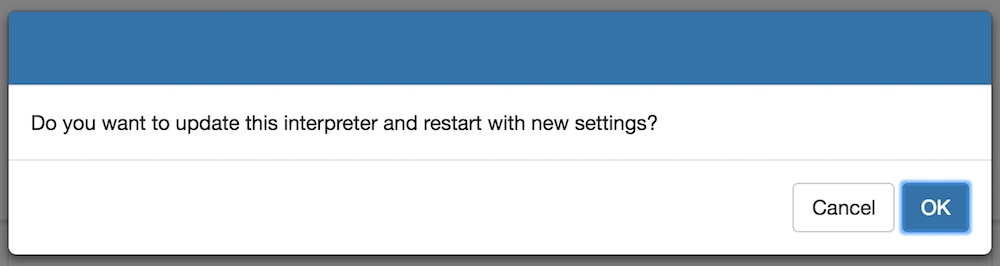
Then click SAVE button. Zeppelin will ask your confirmation to update the settings and restart the interpreter. Click OK to continue. If you want to create it as a separate interpreter, instead of editing JDBC, create a new one and enter the properties and dependencies.
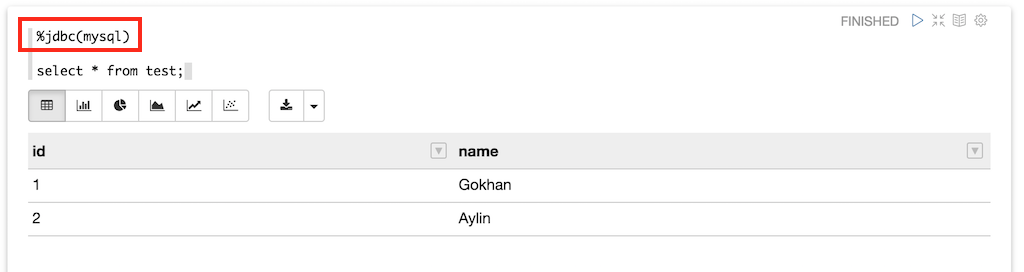
Now it’s time to test our MySQL connection. Open a Zeppelin notebook, add the “%jdbc(mysql)” directive at the start of a paragraph and run a query. If the Zeppelin interpreter gets an error while running the query, it throws a detailed error message, so you can fix the problem easily.
Start the discussion at forums.toadworld.com