Hi,
This article is a continuation of part 5 of this series (click here to see Part 5) in which I will discuss the Native Dynamic SQL and how I used dynamic SQL to solve tough parallel SQL performance issues. I will also illustrate the use of Bulk Collect to use dynamic SQL to populate collections. This material supplements the collections articles (click here to review Part 3 of this series).
Native Dynamic SQL
…or…Execute Immediate syntax was introduced in Oracle7.
The EXECUTE IMMEDIATE syntax is part of the PL/SQL engine (the native part) so no package calls, procedure calls, etc. are needed. Not having to load a PL/SQL package speeds up the execution of your syntax right out of the gate. The internal nature of this command makes it faster than DBMS_SQL (discussed in part 5).
Like DBMS_SQL, EXECUTE IMMEDIATE can work with fetch, collections, objects, and ref cursors, as well as bulk collect. This routine can also execute DDL, PL/SQL blocks, and more. I use this method when executing DDL from a script.
DML statements (and single row query returns) have three cursor attributes: SQL%FOUND, SQL%NOTFOUND, and SQL%ROWCOUNT.
The syntax is simple. EXECUTE IMMEDIATE and a valid SQL statement, or a string containing a valid SQL statement.
As withDBMS_SQL, do not include a ‘;’ at the end of the string.
There are three syntax options:
- INTO – selects a single row returned value into these variables
- USING – passes any bind variables to the SQL text
- RETURNING INTO – standard returning clause
**Note** – perhaps resolve the bind variables in the SQL text prior to execution.
**Tip** – use ‘’’’ (four single quotes) to put a single quote into a string.
When the SQL will return more than one row, or where row processing is desired, the SQL will need to work with a cursor. Weak ref cursors are perfect for this task because they have no defined column characteristics. Fetch and bulk collect syntax can also be used to populate a collection then work with the rows using the collection processing syntax. Yet another method of processing multiple rows is using the DBMS_SQL package discussed in Part 5 of this series.
1: TYPE Weak_Cursor IS REF CURSOR;
2: W_CurWeak_Cursor;
3: Begin
4: OPEN W_Cur for ‘<SQL>’[ USING <bind var>];
5: LOOP
6: FETCH W_Cur INTO <var|record type>;
7: EXIT WHEN W_Cur%NOTFOUND;
8: …
9: END LOOP;
Weak Cursor Dynamic SQL Syntax Example
This syntax example would set you up to use a weak cursor. Notice the optional bind variable content at line 4. Also note at line 4 that the <SQL> in quotes can be SQL between quotes or a variable that contains valid SQL code…but not both. Don’t use the single quotes when passing SQL from a variable.
Typically I use the variable name: SQL_TEXT for my SQL. I am usually completing the where clause. I have used this kind of example years ago with character-mode forms so that end users could select various where and order by options that I would append to this text then run the OPEN statement.
1: Declare
2: TYPE Weak_Cursor IS REF CURSOR;
3: W_CurWeak_Cursor;
4: V_emp_rec EMP%ROWTYPE;
5: Begin
6: OPEN W_Cur for ‘SELECT * FROM EMP’;
7: LOOP
8: FETCH W_Cur INTO v_emp_rec;
9: EXIT WHEN W_Cur%NOTFOUND;
10: DBMS_OUTPUT.PUT_LINE(‘Ename = ‘ || v_emp_rec.ename);
11: END LOOP;
12: CLOSE W_Cur;
13: END;
Weak Cursor Code Example
This is a working example using the above-mentioned syntax. This example will loop throughthe EMP table and display the ENAME column data.
1: TYPE <type_name> IS TABLE OF <attribute|record>;
2: <collection name><type_name>;
3: Begin
4: EXECUTE IMMEDIATE ‘<SQL>’
5: [ BULK COLLECT INTO <collection name>;
6: [ USING<bind var>]
7: [ RETURNING BULK COLLECT INTO <collection name>];
Execute Immediate dynamic SQL syntax populating a collection
This example illustrates the Execute Immediate syntax showing the bulk collect and bind variable features as well. Again at line 4, you either supply SQL syntax between the quotes or a variable that contains SQL syntax, but not both.
1: TYPE EMP_TYPE IS TABLE OF EMP.ENAME%TYPE;
2: EMP_TABLE EMP_TYPE;
3: Begin
4: EXECUTE IMMEDIATE ( ‘SELECT ENAME FROM EMP’)
5: BULK COLLECT INTO EMP_TABLE;
6: FOR I IN EMP_TABLE.FIRST .. EMP_TABLE.LAST
7: LOOP
8: DBMS_OUTPUT.PUT_LINE(‘Ename = ‘ || EMP_TABLE(I) );
9: END LOOP;
10: END;
Execute Immediate Dynamic SQL using Bulk Collect Example
This example does the same thing as the above-mentioned weak cursor example but with both fewerlines of code and probably a lot faster row execution. The bulk collect will get all of the rows in a single fetch from the database, whereas the weak cursor will do row-at-a-time processing, fetching 1 row at a time.
The SQL in quotes at line 4 can be contained in a variable and this example would work the same.
1: Create or Replace PROCEDURE INS_LAB_MSG (
2: IN_MSG IN varchar2 )
3: AS
4: Begin
5: EXECUTE IMMEDIATE (‘insert into LAB_MSG values
6: (USER,SYSDATE,:v_msg) ‘)
7: USING IN_MSG;
8: COMMIT;
9: End;
Execute Immediate DML Code Example
This example inserts a row into the LAB_MSG table. The INSERT syntax and the message could be assembled into a single string, eliminating the need for the bind variable. Do notice the bind variable setup at line 2 and 7 with the bind variable being specified at line 6.
Solving Tough Parallel SQL Performance Issues
Oracle’s Cost-Based Optimizer (CBO) does a good job with processing SQL for partitioned objects so that just the partitions that need to be accessed are being processed. This process of accessing just the partitions with the correct data is called pruning. The partitioning key column will need to be referenced in the SQL’s WHERE clause also.
There are some ‘gotcha’s though if you are not careful. If you don’t code the SQL correctly, the result could be a ‘Long Ops’ operation/full table scan across ALL the partitions, no pruning.
Some (not all) of the coding rules are:
- You need to include the partitioning key value in the WHERE clause
- This field cannot be associated with a sub query
- This field should not have any line functions on it as well.
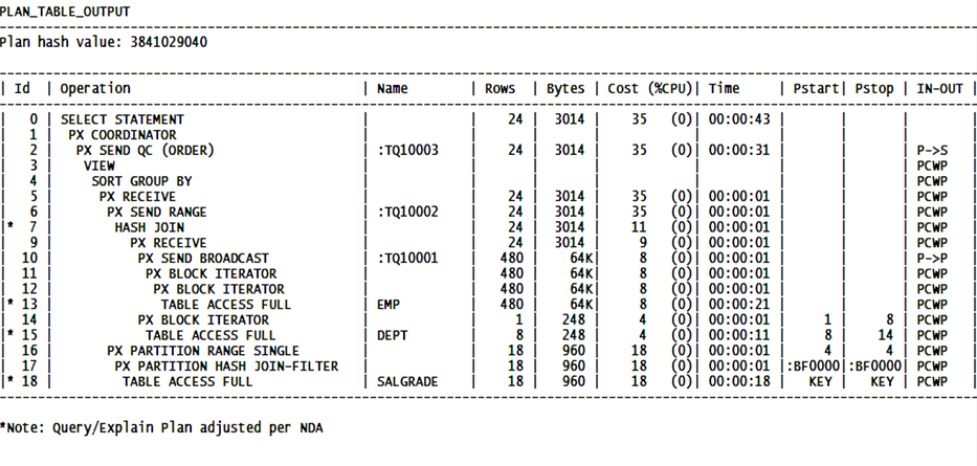
Partitioned SQL Explain Plan
The above is a sample partitioning explain plan from my SQL tuning class. In this example, the DEPT and SALGRADE tables are partitioned objects. What you should see, if the SQL is doing pruning, is beginning and ending partition numbers in the PSTART and PSTOP columns. This tells me that Oracle indeed only plans to process using these partitions.
Notice the very last line, line 18 for SALGRADE. It has a ‘key’ in both the PSTART and PSTOP columns. What the CBO is telling us here is that it does not know how many partitions need to be accessed so will leave the decision till the SQL is actually executed to decide. The optimizer group told me years ago that this isn’t necessarily a bad thing. Maybe it’s not because I only see partitioned SQL explain plans on the ones with serious performance issues.
When I see ‘key’ in these two fields, it tells me that the SQL is probably coded wrong and that this SQL scanned all the partitions, doing no pruning at all.
These are difficult to fix because the people sending me these problems want the quick fix…and the issue is they shouldn’t have coded their SQL the way they coded it…not a quick fix.
So, a client was having problems with their partitioned queries across a very large database. They had/have 365 partitions with 10s of millions of rows per partition.
They would run a short PL/SQL script and it would either run in about 3 minutes or it would light up the ‘Long Ops’ gauge on Enterprise Manager and take well over 20 minutes to run. When the explain plan was reviewed, it too was leaving the pruning to run time and perhaps sometimes Oracle did do dynamic pruning at execution time.
Select sid, serial#, opname, to_char(start_time,’HH24:MI:SS’ START_TIME,
(sofar/totalwork) * 100 PERCENT_COMPLETE
From v$session_longops;
Long Ops SQL
Here is a long ops SQL you can run from Toad. Perhaps Toad already has this report, I know SQL Developer does not. Oracle Enterprise Manager does have a dynamic graph that illustrates this Long Ops operation. If your partitioned query is taking a while to run, run this script and see if your SQL is getting this Long Ops type of operation. If it is, then your SQL is accessing a very large amount of data. Your SQL probably didn’t prune the partitions properly.
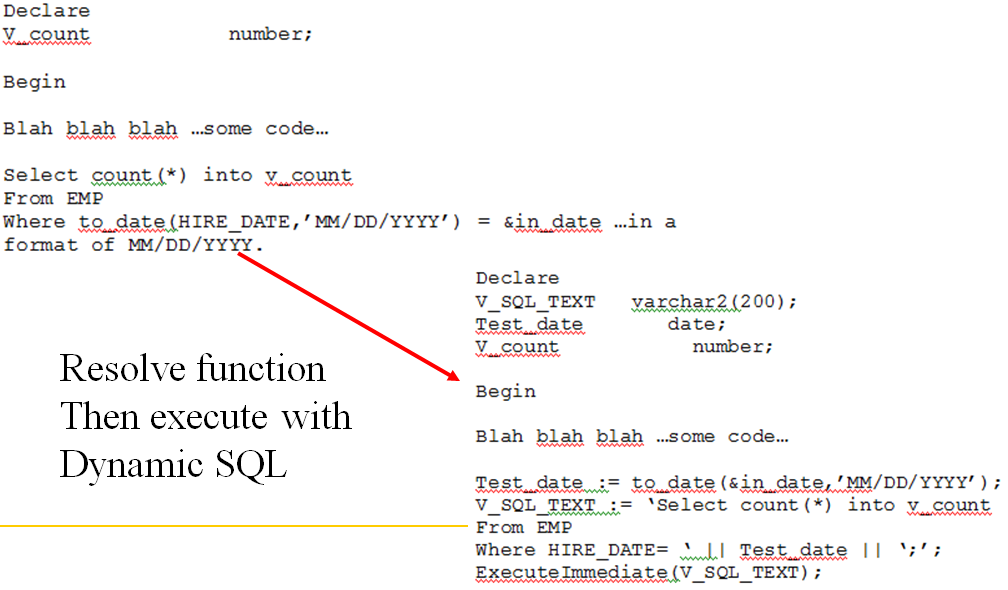
Fixing Parallel SQL Performance Problems with Dynamic SQL
This material comes right out of my Advanced PL/SQL course. The first example is example code of the SQL going against a parallel version of the EMP table. Notice the WHERE clause has a function converting the HIRE_DATE to a specific format. In the secondexample, I work with the variable V_SQL_TEXT. Notice that I resolve the date function by taking the substitution variable and converting it back to a date field! THEN…I recreate the SQL syntax in the V_SQL_TEXT variable and concatenate in the converted date so that the date is now in the same data type as the HIRE_DATE column.
***Note***You can get this same problem with parallel execution when your WHERE clause items are not of the same data type. Behind the scenes, the Oracle optimizer will convert one of the tokens to match the database datatype. You cannot see this code but the result is the same, particularly if the conversion happens on the part of the WHERE clause that contains the partitioned query key.
The lucky part here was twofold: the client was running their problem SQL from a PL/SQL script **AND** the problem was that the partitioning key was inside two nested functions. I believe they were doing a to_char and maybe something else.
Summary
I finished the Dynamic SQL topic illustrating both Weak Cursors and Execute Immediate (Native Dynamic SQL). I gave you useful examples to work from as well as how I used Dynamic SQL to solve problem partitioned SQL performance issues.
I hope you find these tips useful in your day to day use of the Oracle RDBMS.
Dan Hotka
Author/Instructor/Oracle Expert
Start the discussion at forums.toadworld.com