Last week, Oracle Big Data Cloud Service – Compute Edition was upgraded from 17.2.5 to 17.3.1-20. I do not know if the new version is still in testing phase and available to only trial users, but sooner or later the new version will be available to all Oracle Cloud users.
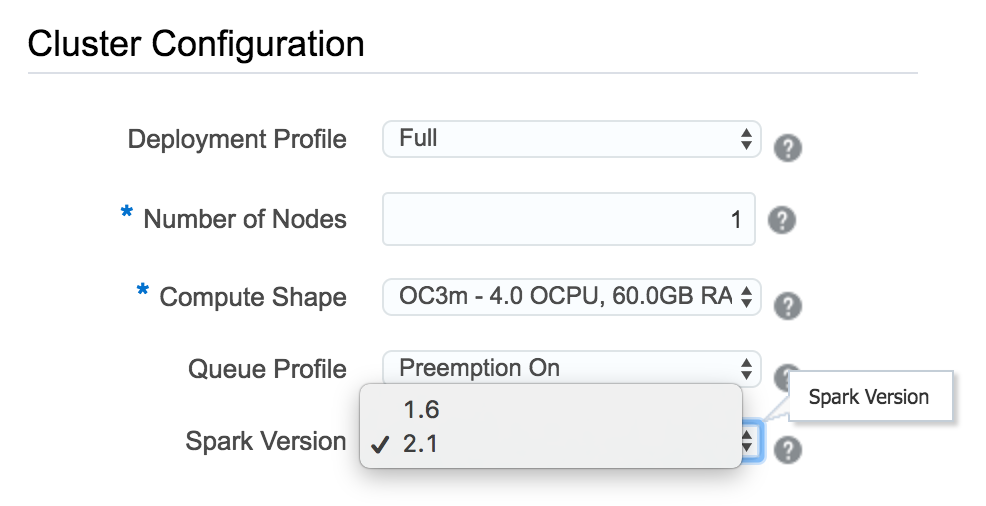
The new version is still based on HDP 2.4.2 but it contains upgrades on two key components: Zeppelin and Spark. Users can now select which Spark version they will use (version 2.1 or version 1.6) when creating the service, and Zeppelin 0.7 installed instead of Zeppelin 0.6. Both of them are important changes.
If you are new to Spark, and do not know which version of Spark you should pick, I recommend you to pick the highest available version (2.1). Don’t worry about stability because only the stable versions are available on Oracle Big Data Cloud Service. Spark 2.1 comes with performance improvements, support for structured streaming and ANSI SQL 2003. There are also changes on APIs for improving usability. On the other hand, if you have already scripts designed to run Spark 1.6, you better read the migration guide before selecting Spark 2.1.
Zeppelin 0.7 comes with lots of improvements including support for Spark 2.1. It doesn’t have HIVE interpreter (which I used my previous blog posts). Instead of hive interpreter, we need to use “jdbc” interpreter. I’ll also write a blog post about it this week.
Start the discussion at forums.toadworld.com