Introduction
An Execution Plan is composed by the steps that the optimizer does in order to process a SQL statement. Oracle Optimizer always tries to find out the best execution plan for a SQL statement, taking into consideration several things, such as access paths, parallelism, statistics, histograms, bind variables, database parameters, etc. However, there are situations when Oracle Optimizer doesn’t create the right execution plan because the information that the optimizer used to create the “best plan” was not correct, not updated, or not sufficient; an example of this (but not the only reason) is when statistics are not updated (stale statistics) and the data has changed considerably in the tables involved in the SQL statement. In such cases, the SQL statement will be executed with an execution plan that the optimizer thinks is the best, but actually it is not.
Oracle has designed several features that make the optimizer aware that there is “something wrong” with the actual execution plan; once the optimizer is aware of that it takes “feedback” and then creates a new execution plan, or takes some others action to “adapt” itself to the environment or data change. The set of features that make the optimizer “adapt” itself to the changes in the environment (for instance, database parameters) or in the data (for instance, skewed data) are called “adaptive features”. In Oracle Database 12.1.0.1 probably the most popular words were “adaptive” and “multi-tenant”; it was the first version with several new features that included the word “adaptive”. For instance, adaptive index compression, adaptive query optimization, adaptive plans, adaptive joins, adaptive parallel and several additional adaptive things!
“Adaptive Features” comprise two categories: “Adaptive Plans” and “Adaptive Statistics”.
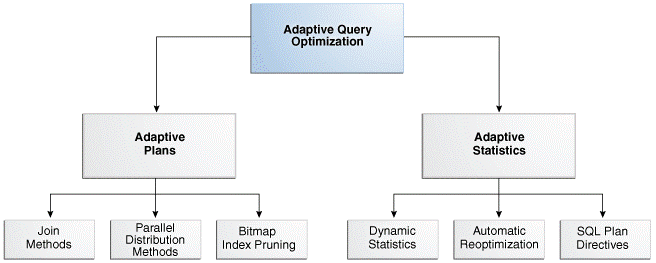
In 12.1.0.1 all the “adaptive” features were controlled by the database parameter “optimizer_adaptive_features”; however, in 12.2.0.1 that changed and now the database parameter “optimizer_adaptive_features” has been broken up into two new database parameters: optimizer_adaptive_plans and optimizer_adaptive_statistics. Each parameter controls a category of Adaptive Features. The database parameter “optimizer_adaptive_features” doesn’t exist in 12.2.0.1.
The definition of the parameter in 12.1.0.1:
- optimizer_adaptive_features enables or disables all of the adaptive optimizer features, including adaptive plan (adaptive join methods and bitmap pruning), automatic re-optimization, SQL plan directives, and adaptive distribution methods.
The definition of the parameters in 12.2.0.1:
- optimizer_adaptive_plans controls adaptive plans. Adaptive plans are execution plans built with alternative choices that are decided at runtime based on statistics collected as the query executes.
- optimizer_adaptive_statistics controls adaptive statistics. Some query shapes are too complex to rely on base table statistics alone, so the optimizer augments these statistics with adaptive statistics.
Oracle SQL Plan Directives is part of the category “Adaptive Statistics”. Basically, they are notes that the optimizer writes and stores in the database to “adapt” itself to the environment or data changes. For example, if the optimizer sees that the actual rows are considerably different than the estimated rows, then the optimizer writes a note to “remember” what happened, so that in the next execution of the same SQL statement (or one with the same query expressions), the optimizer can take actions to fix it. These notes taken by the optimizer are called “SQL Plan Directives”. SQL Plan Directives are not tied to a specific SQL_ID. SQL Plan Directives are based on a query expression rather than at the SQL statement level. This makes the SQL Plan Directives usable for others SQL_IDs as long as the query expression is the same. SQL Plan Directives can be queried using the views DBA_SQL_PLAN_DIR_OBJECTS and DBA_SQL_PLAN_DIRECTIVES.
If you want to see a comparison between SQL Plan Directives in 12.1 and 12.2 you can read this good article written by Mauro Pagano.
Oracle automatically handles all related to SQL Plan Directives; it creates and maintains them. The only operations allowed by Oracle for SQL Plan Directives are the following:
- Flush the SQL Plan Directives to disk.
- Delete a SQL Plan Directive
- Export a SQL Plan Directive
- Import a SQL Plan Directive.
How to flush the SQL Plan Directives to disk: When a SQL Plan Directive is created, it is created only in memory. Oracle flushes all the new SQL Plan Directives to disk every 15 minutes. However, if you want to flush the SQL Plan Directives manually you can use the following sentences:
BEGIN DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE; END; /
Delete a SQL Plan Directive: To delete a SQL Plan Directive you can use the following SQL statement where the only value requested is the ID of the SQL Plan Directive:
SQL> exec dbms_spd.drop_sql_plan_directive ('<SPD ID>'); PL/SQL procedure successfully completed.
Export and Import SQL Plan Directives: SQL Plan Directives are transported to others databases following the same method that we use to transfer SQL Tuning Sets. This article doesn’t cover those steps, but for more details you can see the Metalink Note: How to Transport SQL Plan Directives (SPD) From One Database to Another (Doc ID 2064227.1)
Now after covering these useful concepts, let’s do an example!
In this example I am using Oracle Database 12.2.0.1 Enterprise Edition. I have the table dgomez.employee:
SQL> desc dgomez.employee Name Null? Type --------- -------- ---------------------------- AGE NUMBER NAME VARCHAR2(20) COUNTRY VARCHAR2(20)
In the table I have only one row with the data of one employee.
select /*+gather_plan_statistics*/ * from dgomez.employee e where e.country='Guatemala' and e.age=21; AGE NAME COUNTRY ---------- ----------- -------------------- 21 Deiby Guatemala
You can see that the Estimated Rows (E-Rows) is the same as the value of Actual Rows (A-Rows):
select * from table(dbms_xplan.display_cursor(format=>'ALLSTATS LAST')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------ SQL_ID bmx5dfgyzm2ag, child number 0 ------------------------------------- select /*+gather_plan_statistics*/ * from dgomez.employee e where e.country='Guatemala' and e.age=21 Plan hash value: 2119105728 ---------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 7 | 6 | |* 1 | TABLE ACCESS FULL| EMPLOYEE | 1 | 1 | 1 |00:00:00.01 | 7 | 6 | ---------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(("E"."COUNTRY"='Guatemala' AND "E"."AGE"=21)) 19 rows selected.
Now let’s query the view v$sql; this view has a column called “IS_REOPTIMIZABLE”. The definition of this column is the following:

We can see that the SQL statement we executed has not been marked as reoptimizable:
select sql_id, child_number, is_reoptimizable, sql_text from v$sql where sql_text like '%dgomez%' and sql_text not like '%insert%'; SQL_ID CHILD_ NUMBER I SQL_TEXT ------------- ------------ - ---------------------------------------- bmx5dfgyzm2ag 0 N select /*+gather_plan_statistics*/ * fro m dgomez.employee e where e.country='Gua temala' and e.age=21 PL/SQL procedure successfully completed.
Now I will insert several others employees in order to create a difference between the estimated rows and the actual rows. Let’s execute the SQL statement again. I would like to highlight the fact that I had to execute this SQL statement four times in order to make it reoptimizable; in some other cases I had to execute it more times and in some others less times.
select /*+gather_plan_statistics*/ * from dgomez.employee e where e.country='Guatemala' and e.age=21; AGE NAME COUNTRY -- -------- -------------------- 21 Jose Guatemala 21 Maria Guatemala 21 Josh Guatemala 21 Julio Guatemala 21 Pedro Guatemala 21 Marvin Guatemala 21 Oscar Guatemala 21 Mauricio Guatemala 21 Gabriel Guatemala 21 Jonathan Guatemala 21 Lucrecia Guatemala 21 Alex Guatemala 21 Alvaro Guatemala 21 Alan Guatemala 21 Deiby Guatemala 15 rows selected.
We can see now that there is a difference between the Actual Rows and the Estimated Rows:
select * from table(dbms_xplan.display_cursor(format=>'ALLSTATS LAST')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------- SQL_ID bmx5dfgyzm2ag, child number 0 ------------------------------------- select /*+gather_plan_statistics*/ * from dgomez.employee e where e.country='Guatemala' and e.age=21 Plan hash value: 2119105728 -------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 15 |00:00:00.01 | 8 | |* 1 | TABLE ACCESS FULL| EMPLOYEE | 1 | 1 | 15 |00:00:00.01 | 8 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(("E"."COUNTRY"='Guatemala' AND "E"."AGE"=21)) 19 rows selected.
The SQL statement was finally marked as reoptimizable. This is because the optimizer saw that there was a difference between the estimated rows and the actual rows.
SQL_ID CHILD_NUMBER I SQL_TEXT ------------- ---------- - ---------------------------------------- bmx5dfgyzm2ag 0 Y select /*+gather_plan_statistics*/ * fro m dgomez.employee e where e.country='Gua temala' and e.age=21 PL/SQL procedure successfully completed.
Also, the optimizer wrote some “notes” (SQL Plan Directives) to remember in the next execution that there was something wrong with the estimated rows:
select o.directive_id id, owner, o.object_name, o.object_type, d.state, d.reason, d.notes from DBA_SQL_PLAN_DIR_OBJECTS o, DBA_SQL_PLAN_DIRECTIVES d where o.OWNER='DGOMEZ' and o.directive_id=d.directive_id; ID OWNER OBJECT_NAM OBJECT_TYP STATE REASON NOTES -------------------- ------ ---------- ---------- ------ -------------------- -------------------- 14767378624474121740 DGOMEZ EMPLOYEE COLUMN USABLE SINGLE TABLE CARDINA <spd_note> LITY MISESTIMATE <internal_state>NE W</internal_state> <redundant>NO</red undant> <spd_text>{EC(DGOM EZ.EMPLOYEE)[AGE, CO UNTRY]}</spd_text> </spd_note> 14767378624474121740 DGOMEZ EMPLOYEE COLUMN USABLE SINGLE TABLE CARDINA <spd_note> LITY MISESTIMATE <internal_state>NE W</internal_state> <redundant>NO</red undant> <spd_text>{EC(DGOM EZ.EMPLOYEE)[AGE, CO UNTRY]}</spd_text> </spd_note> 14767378624474121740 DGOMEZ EMPLOYEE TABLE USABLE SINGLE TABLE CARDINA <spd_note> LITY MISESTIMATE <internal_state>NE W</internal_state> <redundant>NO</red undant> <spd_text>{EC(DGOM EZ.EMPLOYEE)[AGE, CO UNTRY]}</spd_text> </spd_note>
The TYPE of this Directive DYNAMIC_SAMPLING:
SQL> select o.directive_id id, d.type from DBA_SQL_PLAN_DIR_OBJECTS o, DBA_SQL_PLAN_DIRECTIVES d where o.OWNER='DGOMEZ' and o.directive_id=d.directive_id; ID TYPE -------------------- ----------------------- 14767378624474121740 DYNAMIC_SAMPLING 14767378624474121740 DYNAMIC_SAMPLING 14767378624474121740 DYNAMIC_SAMPLING
You can see several rows returned, but if you look at the “ID” column, you will see that only one SQL Plan Directive was created.
Now let’s execute again the SQL statements and let’s see what happens:
select /*+gather_plan_statistics*/ * from dgomez.employee e where e.country='Guatemala' and e.age=21; AGE NAME COUNTRY --- -------- -------------------- 21 Jose Guatemala 21 Maria Guatemala 21 Josh Guatemala 21 Julio Guatemala 21 Pedro Guatemala 21 Marvin Guatemala 21 Oscar Guatemala 21 Mauricio Guatemala 21 Gabriel Guatemala 21 Jonathan Guatemala 21 Lucrecia Guatemala 21 Alex Guatemala 21 Alvaro Guatemala 21 Alan Guatemala 21 Deiby Guatemala 15 rows selected.
The SQL Plan Directive was used, as well as Dynamic Sampling Statistics, which made the optimizer fix the difference between estimated rows and actual rows. With the help of SQL Plan Directives, the optimizer was able to adapt itself to the change; in this case, a change in the data (several more rows were inserted). In this example Dynamic Sampling Statistics was used, but SQL Plan Directives can remind the optimizer to take other actions in addition to Dynamic Sampling Statistics. (At least, it was designed to have more TYPES, but at this time Dynamic Sampling Statistics (and its sub type DYNAMIC_SAMPLING_RESULT) is the only TYPE existing, as Mauro Pagan explains in this presentation.)
PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------- SQL_ID bmx5dfgyzm2ag, child number 0 ------------------------------------- select /*+gather_plan_statistics*/ * from dgomez.employee e where e.country='Guatemala' and e.age=21 Plan hash value: 2119105728 ------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 15 |00:00:00.01 | 8 | |* 1 | TABLE ACCESS FULL| EMPLOYEE | 1 | 15 | 15 |00:00:00.01 | 8 | ------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(("E"."COUNTRY"='Guatemala' AND "E"."AGE"=21)) Note ----- - dynamic statistics used: dynamic sampling (level=2) - 1 Sql Plan Directive used for this statement 24 rows selected.
And after reoptimizing the SQL Statement, the query is now marked as not reoptimizable:
SQL_ID CHILD_ NUMBER I SQL_TEXT ------------- ------ - ---------------------------------------- bmx5dfgyzm2ag 0 N select /*+gather_plan_statistics*/ * fro m dgomez.employee e where e.country='Gua temala' and e.age=21 PL/SQL procedure successfully completed.
A new note was added to the same SQL Plan Directive.
select o.directive_id id, owner, o.object_name, o.object_type, d.state, d.reason, d.notes from DBA_SQL_PLAN_DIR_OBJECTS o, DBA_SQL_PLAN_DIRECTIVES d where o.OWNER='DGOMEZ' and o.directive_id=d.directive_id; ID OWNER OBJECT_NAM OBJECT_TYP STATE REASON NOTES -------------------- ------ ---------- ---------- ------ -------------------- -------------------- 14767378624474121740 DGOMEZ EMPLOYEE COLUMN USABLE SINGLE TABLE CARDINA <spd_note> LITY MISESTIMATE <internal_state>MI SSING_STATS</interna l_state> <redundant>NO</red undant> <spd_text>{EC(DGOM EZ.EMPLOYEE)[AGE, CO UNTRY]}</spd_text> </spd_note> 14767378624474121740 DGOMEZ EMPLOYEE COLUMN USABLE SINGLE TABLE CARDINA <spd_note> LITY MISESTIMATE <internal_state>MI SSING_STATS</interna l_state> <redundant>NO</red undant> <spd_text>{EC(DGOM EZ.EMPLOYEE)[AGE, CO UNTRY]}</spd_text> </spd_note> 14767378624474121740 DGOMEZ EMPLOYEE TABLE USABLE SINGLE TABLE CARDINA <spd_note> LITY MISESTIMATE <internal_state>MI SSING_STATS</interna l_state> <redundant>NO</red undant> <spd_text>{EC(DGOM EZ.EMPLOYEE)[AGE, CO UNTRY]}</spd_text> </spd_note> 7617691850148384040 DGOMEZ EMPLOYEE TABLE USABLE VERIFY CARDINALITY E <spd_note> STIMATE <internal_state>NE W</internal_state> <redundant>NO</red undant> <spd_text>{(DGOMEZ .EMPLOYEE, num_rows= 15) - (SQL_ID:2zbnc0 ugm2qzy, T.CARD=15[- 2 -2])}</spd_text> </spd_note>
This last SQL Plan Directive is of type “DYNAMIC_SAMPLING_RESULT”:
SQL> select to_char(o.directive_id) id, d.type from DBA_SQL_PLAN_DIR_OBJECTS o, DBA_SQL_PLAN_DIRECTIVES d where o.OWNER='DGOMEZ' and o.directive_id=d.directive_id; ID TYPE -------------------------------------- ----------------------- 14767378624474121740 DYNAMIC_SAMPLING 14767378624474121740 DYNAMIC_SAMPLING 14767378624474121740 DYNAMIC_SAMPLING 7617691850148384040 DYNAMIC_SAMPLING_RESULT
How to disable SQL Plan Directives: If you want to disable only SQL Plan Directives you can set the following parameters to ‘0’:
This will stop creation of new SQL Plan Directives:
SQL> alter system set "_sql_plan_directive_mgmt_control"=0; System altered.
This will stop using existing SQL Plan Directives:
SQL> alter system set "_optimizer_dsdir_usage_control"=0; System altered.
You can disable SQL Plan Directives indirectly if you set the following parameter:
- optimizer_adaptive_reporting_only = “TRUE”.
- optimizer_features_enable < 12.1.0.1
How to disable all the features in “Adaptive Statistics”:
SQL> alter system set optimizer_adaptive_statistics=false; System altered.
How to disable all the features in “Adaptive Plans”:
SQL> alter system set optimizer_adaptive_plans=false; System altered.
How to enable SQL Plan Directives:
- The parameter _sql_plan_directive_mgmt_control must not be set to 0
- The parameter _optimizer_dsdir_usage_control must not be set to 0.
- The parameter optimizer_adaptive_statistics must be set to “TRUE”.
- The parameter optimizer_adaptive_reporting_only must be set to “FALSE”.
- The parameter optimizer_features_enable must be set to a value >= 12.1.0.1
Conclusion
Oracle Database has been improving its features with every version, and in 12c several adaptive features were introduced. SQL Plan Directives are notes that help the optimizer remember things in the next execution; this allows the optimizer to adapt to changes. We saw a step-by-step example in this article, and we explained how to enable and disable SQL Plan Directives and the others database parameters related to adaptive features.
Start the discussion at forums.toadworld.com